ChatGPT의 전신인 InstructGPT는 GPT-3를 강화학습 기법으로 fine-tuning하여 사용자의 의도에 맞는 답변을 생성하는 것을 목표로 하였으며, Fine-tuning용 데이터를 구축하기 위하여 40명의 Labeler를 고용하였음. 아래는 InstructGPT의 Training process임
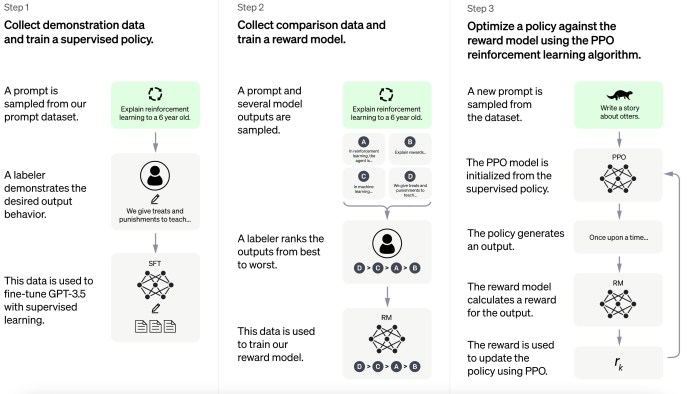
Step 1 (Supervised Fine-tuned Model) :
InstructGPT 논문에서 설명한 Step1 구성 방법
1. Demonstration Data (prompt-response 쌍) 수집, 13k DataSet
- prompt : labeler가 직접 작성 + Open AI의 API를 통해 수집된 실제 사용자들의 prompt
- response : 주어진 prompt에 대한 답변을 labeler(약 40명의 labeler 참여)가 직접 작성
2. 위 데이터셋을 활용하여 GPT-3 fine-tuning (supervised learning)
- 1.3B, 6B, 175B, 3가지 버전 모델 학습 진행
Step 2 (Reward Model 학습)
1. Comparison Data : 각 prompt에 대응하는 4~9개의 response 생성 결과물을 대상으로 labeler가 선호도 순위를 매김 (총 3만3천개의 prompts)
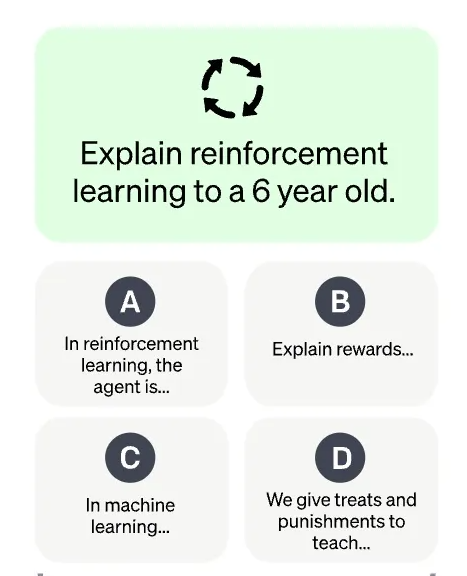
2. Step 2 그림 세분화 설명 (1) : 증강 학습에 대하여 6살 아이에게 설명 하라는 Prompt를 넣었을 때, 아래 그림 (A, B, C, D) 4개의 답변이 response 됨
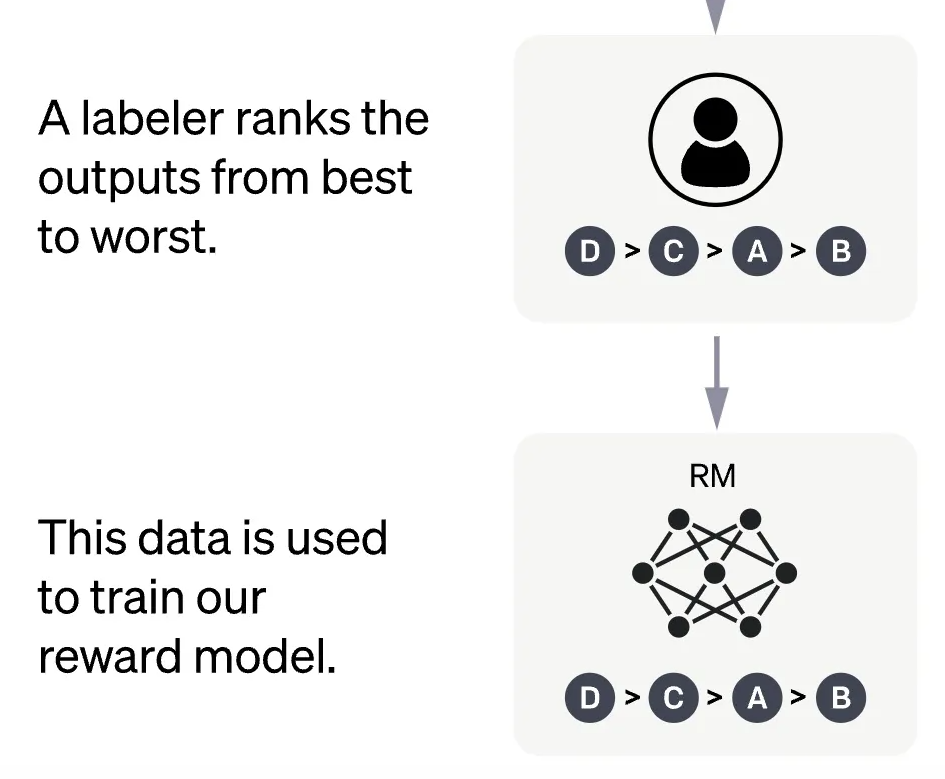
3. Step 2 그림 세분화 설명 (2) : labeler는 4개의 답변에 대하여 가장 좋은 답변 부터 나쁜 답변까지 순위를 매김
4. Step 2 그림 세분화 설명 (3) : 이렇게 구성된 RM 데이터셋은 prompt, response, 순위로 구성되어 있고, 이 데이터셋을 사용해서 Reward Model을 학습함.
Step 3 (PPO 강화 학습 알고리즘을 사용하여 reward model에 대한 policy 최적화)
1. Step 2에서 학습된 Reward Model을 reward function으로 활용하여 PPO 강화 학습 알고리즘을 사용하여 reward를 최대화 하도록 GPT-3를 fine-tuning (31,000개의 prompts 가 사용됨)
2. 본 과정을 통하여 완성된 모델이 바로 InstructGPT 임
정리 하며...
1. Step1에서는 지도 학습으로 GPT-3 를 튜닝하였음.
- 지도 학습이 필요했던 이유는 "우리가 원하는 대답"을 직접 학습해 줘야할 필요가 있었음
- 그러나, Label 데이터 양의 한계로 인하여 저자들은 모델의 대답에 피드백을 해주며 무한히 학습 할 수 있는 강화학습을 선택하였음
2. 강화학습을 사용하려면 보상을 결정해 줄, 즉 모델의 대답에 대하여 평가해줄 내용이 필요한데, 이를 위해 Reward Model을 만드는 과정이 Step 2임
3. 이렇게 만든 RM을 사용해서 강화 학습 방식으로 최종 학습한 모델이 InstructGPT임
관련논문
Training language models to follow instructions with human feedback (URL : https://arxiv.org/abs/2203.02155)
'AI모델 훈련 기법' 카테고리의 다른 글
| AI모델 성능 평가 (1) : 과적합(overfitting)과 과소적합(underfitting) 판단기준 및 해결방법 (2) | 2024.10.14 |
|---|---|
| RLHF (Human 피드백을 통한 강화 학습, Reinforcement Learning from Human Feedback) 사용 사례 (13) | 2024.10.05 |